——深入理解卡尔曼滤波器(1)
在本科阶段学习自动控制理论的时候,无论是经典控制理论还是现代控制理论之中我们往往关心系统的动态性能,系统的稳定时间,系统的稳态误差……其中令我感到最为难以理解的就是对于噪声(Noise)的忽视。在我的印象之中对于噪声的详细讨论仅仅在教科书的时域分析-稳态误差之中享有一个符号\(e_{ssn}\)。这让热爱实践的我感到极大的不满:在真实的工程之中,平滑输出的传感器几乎仅仅存在于工程师们意淫的迷梦之中——天空雷声炸响,你的滤波器闪亮登场!
本页内容概览
1. 到底啥叫个滤波器——理解
在常年的工程实践之中,或许大家多多少少都被精度不足波动爆炸的ADC折磨过——你给我解释解释为什么我水箱里180L的水温度在短短10s之内从\(40^\circ C\)到\(60^\circ C\)反复波动???更加噩梦的是这种噪声在数学上的模型是这样的:
- 该函数\(e(t)\)处处连续
- 该函数\(e(t)\)处处不可导
- 该函数\(e(t)\)无法使用分析方法进行定义
这就导致我们在对传感器数据进行微积分操作:例如通过电机屁股上的磁编码器解算出角速度(微分操作)或者通过IMU的角速度和加速度计算出当前载体的欧拉角(积分操作)时得到的结果总是具有”城门楼子”和”胯骨轴子“的区别——这甚至会导致系统极大的不确定性和不稳定性的出现。
那么这时候怎么办呢,我们很自然的认为我们的信号之中混入了一个叛徒——扰动(Disruption)——所以说将这个噪声(Noise)信号去掉即可!那么这个我们想要去掉的噪声信号就是滤波器过滤掉的”波”。
1.1 从状态观测器开始谈起
为了便于后续推导展开以及直击问题的本质,全文将采用状态空间方法对系统进行描述。考虑到从实际问题出发,我们不妨将这个状态空间建模的过程进行一个梳理,在这里我们选取一个标准的积分链(Integral Chain)类型的系统作为例子,考虑这样一个单维度运动小车(是的,还是一个小车,我爱车车),并且基于简化系统的目的我们做出以下设定:
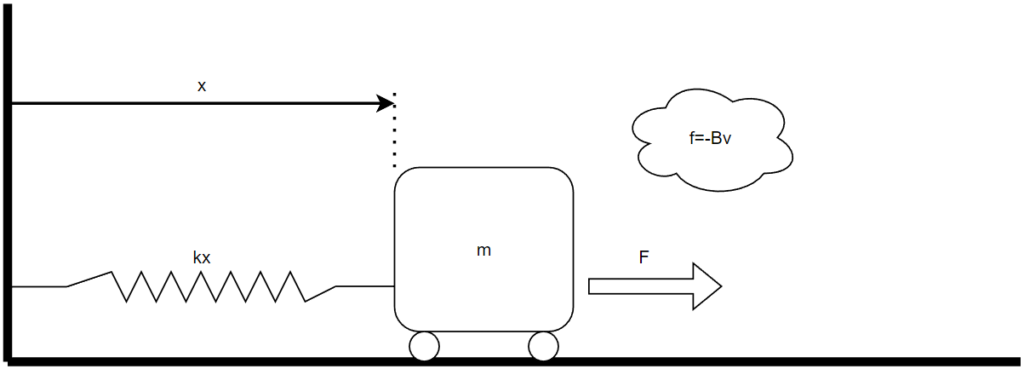
- 小车的质量为\(m\),行驶在一片绝对光滑的地面上——没有摩擦力!
- 地面上是没有摩擦力的,但是小车系统处于一片理想的流体之中,流体的阻尼系数为\(B\),在图中定义的位移量\(x\)的正方向上显然有速度\(v\),流体的阻力是\(-Bv\)
- 同时小车的尾巴上还有一个理想弹簧,弹簧的胡克系数是\(k\),虽然图中没有标注胡克力方向,但这是常识——弹簧的力总是与它形变的方向相反
- 同时,小车还受到一个外部牵引力\(F\),只有这个力是我们可以随意改变的
那么假设我们想较为精确的控制小车的位置\(x\)的话,显然我们不得不同时控制好位移的各阶导数也就是\(\dot x=v\)速度和\(\ddot x=a\)加速度,并且我们可以列出一个微分方程:
$$\tag{1-1}
\begin{cases}\dot x&=v\\ \dot v&=a\\
ma&=F-kx-Bv
\end{cases}
$$
非常自然地,我们发现,只要讨论\(x,v\)两个量及其导数那么我们需要控制的量和系统动态微分方程就结合在了一起。凡学习过线性代数的同学不难想到为什么不可以定义一个向量\([x,v]^T\)来表示我们想要控制的所有变量呢,并且显然这个向量\(\in\mathcal{R}^2\),这个二维空间其实就是我们平常说的状态空间(State Space)!现在假设我们仅关心位置作为输出也就是\(y=x\),这其实就是一个SISO系统并且这个系统不难表示为矩阵的形式:
$$\tag{1-2}
\begin{cases}
\begin{bmatrix}\dot x\\ \dot v\end{bmatrix}&=
\begin{bmatrix}0&1\\-\frac km&-\frac Bm\end{bmatrix}\begin{bmatrix}x\\ v\end{bmatrix}
+\begin{bmatrix}0\\\frac 1m\end{bmatrix}F\\
y&=\begin{bmatrix}1&0\end{bmatrix}\begin{bmatrix}x\\v\end{bmatrix}
\end{cases}
$$
以上系统就是现代控制理论之中最核心最基础的状态空间表达形式,有现代控制理论基础的同学不难发现这个系统是完全能观能控的——当然在实际情况之中我们会碰到系统的非最小实现情况也就是不完全能观或者不完全能控,但是这不利于我们现在的讨论,故而使用这种最简单的系统。我们不难想象这类系统的表达通式:
$$\tag{1-3}
\begin{cases}
\dot x=Ax+Bu\\ y=Cx+Du
\end{cases}
$$
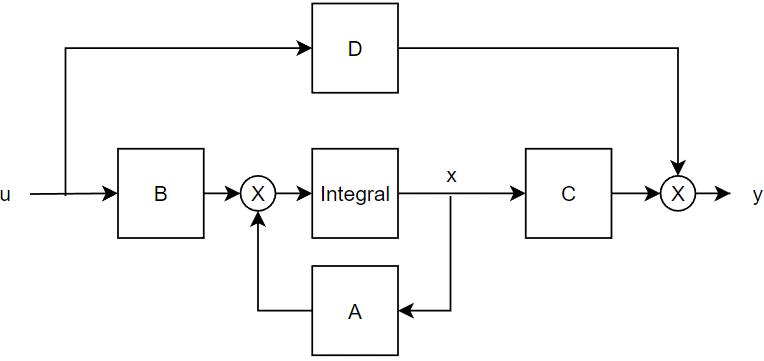
在上方的示意图之中\(x,y,u\)都是向量,分别表示系统状态、系统输出、系统输入。我们在经典控制理论之中谈论的”n阶系统”其实就是向量\(x\)的维度,只不过在经典控制之中我们一般谈论的是SISO系统故而输入和输出只有单一维度。矩阵\(A,B,C,D\)分别表示:系统状态转移矩阵、系统输入矩阵、系统输出矩阵和直接控制矩阵,一般而言\(D\)矩阵不存在,就像是我们举的例子一样。
这里许多同学可能存在一个误区:你现在讨论的不是一个”裸“系统么——我还没有添加任何控制器和控制律呀,那么为什么\(A\)矩阵已经处于反馈回路,也就是一个闭环之上了呢?这种误区主要在于以下两个方面的概念混淆:
- 闭环,或者说反馈事实上是一种性质。也就是说反馈并不是人为添加控制之后才有的,在自然界和工业界的很多”裸系统“之中这种性质都存在:例如电机转速增大-反向电动势增大-加速度减小-转速上升率减小,这就是电机之中自带的闭环特性。
- 上图上式之中闭环特性事实上是作用于系统的状态变量\(x\)上的,这个状态变量和输出之间还有一个输出矩阵\(C\)作为阻隔,只不过我们举的例子比较简单以致于出现了这种错觉,在系统的输出和输入事实上是没有直接的反馈的。
明确了以上概念之后我们就应当开始对系统进行控制——无论什么高深的控制策略其根本必定是落在改变系统的输入\(u\)之上,基于系统的能控性这种改变会作用于\(x\)上并且最终影响输出。所以所谓设计控制器和控制律本质就是:如何得到一个合适的输入?如何做出这样一套映射关系:我们想要的参考输出(Reference Output)-对应的期望输入(Design Input)-实际系统的输入\(u\)。这里以现代控制理论之中的状态反馈为例,我们可以对系统进行如下调整:
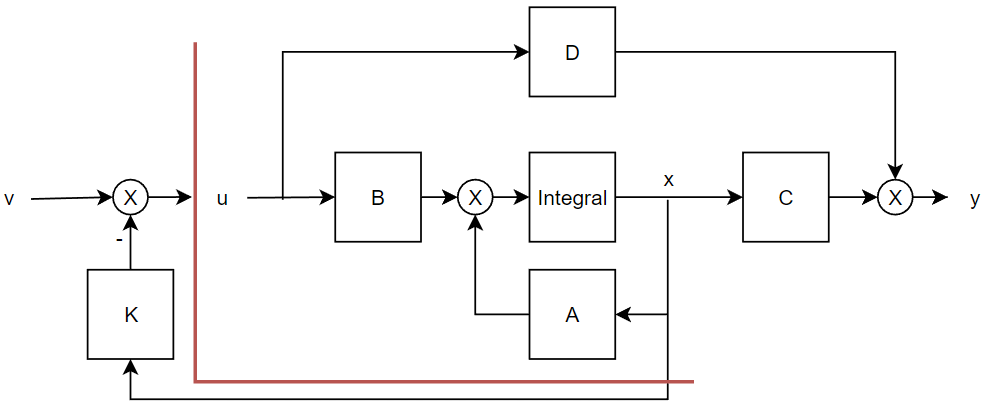
可以看到在红色外框之外我们添加了一部分结构,这种结构就被称为状态反馈器,可以发现矩阵\(K\)在状态变量\(x\)和输入之间建立了反馈关系,当然如果这种反馈建立在输出和输入之间就称之为输出反馈器。这种状态反馈器的详细表述和推导在这里不做赘述,这不是本文的主题,这部分内容应当在现代控制理论基础之中进行阐述。
但是我们在抽象结构之中添加了这一部分,那么对应到现实系统之中是什么呢?我们大可以说原来的\(u\)就是驱动力\(F\)我们现在将矩阵\(K\)和虚拟输入\(v\)以及相关运算全部放在某个嵌入式系统之中执行,这是没有问题的——但接踵而来的致命问题就是:你咋知道\(x\)是多少嘞??谈到这里我们的配角一号终于要登场了——我们需要某种测量设备可以测得我们想要的状态变量!那么我们对现实系统和抽象系统都浅浅的做出一些改变:

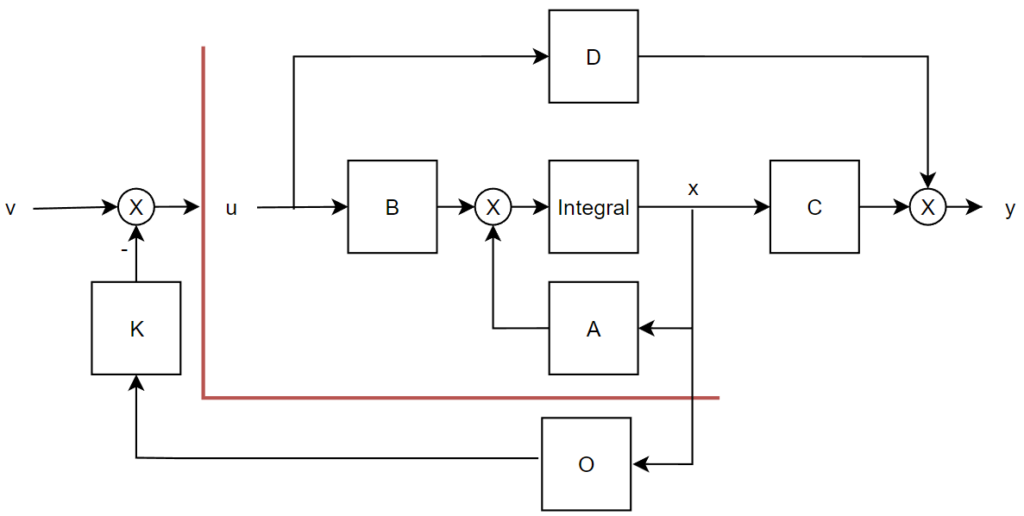
右图之中可以发现添加了一个全新的环节(注意,我没有说这是个简单的矩阵!)\(O\)这个环节表示某种可以测量状态变量\(x\)的方法。这种方法实现的方式多种多样,就像是左图之中蓝色的仪表图标一样,这种仪表可以测得距离,例如超声波测距、激光ToF测距等等……当然测出的裸数据往往是ADC读出的传感器电压或者高级一点的传感器支持总线直接传递数字数据——它们需要经过单位换算等等运算才能变成我们熟知的m,cm等单位,但是这种简单的线性运算可以合并到矩阵\(K\)之中去做。
真正令人心痛的是:我们的状态变量有二维,第二维度是速度,我们现在只有距离信息这可咋办嘛!有的朋友给出了相当直接的方法:对距离求微分!即使我们认为在代码之中执行这种微分不会引起系统高频噪声,离散的差分运算和实际连续时间系统(Continuous-Time System)之间的误差我们也抹去,还是有一个不容忽视的问题——这个数据事实上不是你测出来的,是你算出来的!在代入我们忽略掉的种种误差之后,这个结论就更加恐怖了——你的数据既不来源于测量(Measure)也不来源于精确的计算(Calculate)而是来源于一个字面意义就令人不安的词汇:估计(Estimate)。到这里我们就可以理解什么叫做控制理论和控制系统之中的估计了。
因此我们需要一种能够将这种不稳定不精确的数据稳定化精确化的工具,我们不妨考虑一种最极端的状况也就是:我们不能够直接获取任何一维度的数据,也不能通过简单的微分或者积分运算从已有维度推知其他维度,那怎么办呢?开摆!既然我们已经无法获取精确数据了,那么干脆将所有数据全部模拟计算,反正我们已经得到了控制系统的动态微分方程——也就是一个可以运算的数学模型,那么我们只要在计算设备的内存之中虚拟一个系统然后镜像的对虚拟系统和实际系统进行操作不就可以了么!我们将镜像系统的状态变量称为\(\hat x\)也就是\(x\)的估计量,由于我们仅关心状态不关心输出,所以这个虚拟的系统可以认为是:
$$\tag{1-4}
\dot{\hat x}=A\hat x+Bu
$$
但是到这里我们还是没有解决估计量和真实量之间的误差(Error)的问题,这时候我们注意到:\(y\)是系统对外暴露的特性,是一定能够测得的,那么我们可以将虚拟系统代入输出方程并与真实系统进行比较从而这样处理这个误差:
$$\tag{1-5}
\begin{cases}
e&=x-\hat x\\
y&=Cx+Du\\
\hat y&=C\hat x+Du
\end{cases}\Rightarrow
y-\hat y=(Cx+Du)-(C\hat x+Du)=C(x-\hat x)=Ce
$$
而后,我们将这个误差代入到虚拟系统之中进行校正,一旦误差为0那么虚拟系统与原系统毫无区别,而误差不为0时就代入误差进行了计算:
$$\tag{1-6}
\begin{align}
\dot{\hat x}&=A\hat x+Bu+H(y-\hat y)\\
&=A\hat x+Bu+HC(x-\hat x)\\
&=(A-HC)\hat x+HCx+Bu\\
\dot x&=Ax+Bu\\
\dot x-\dot{\hat x}&=(Ax+Bu)-[(A-HC)\hat x+HCx+Bu]\\
&=(A-HC)(x-\hat x)\\
e&=x-\hat x\\
\dot e&=\dot x-\dot{\hat x}\\
\dot e&=(A-HC)e
\end{align}
$$
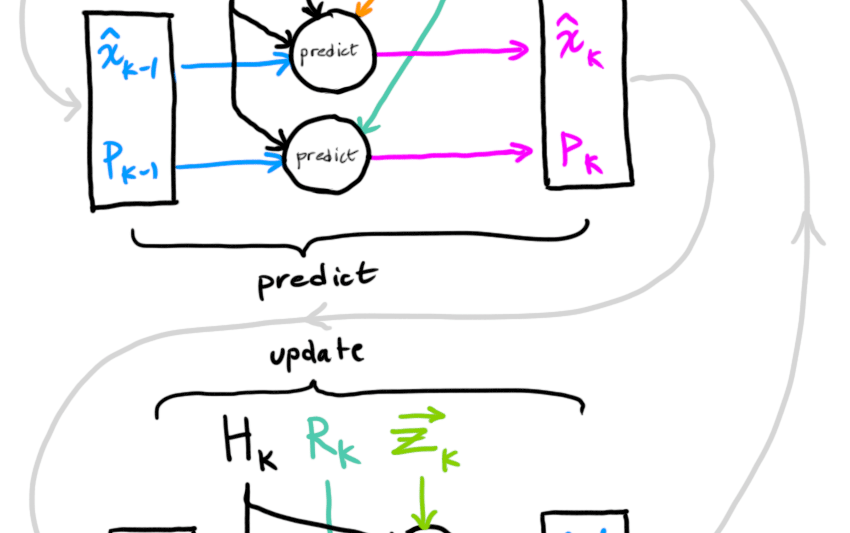
可以看到这样一来我们就构造了一个寓于真实系统和模拟系统之间的隐性的误差系统,这个误差系统也存在一个闭环反馈,只要这个闭环反馈最终的值为\(\lim\limits_{t\to\infty}e(t)=0\)就可以保证我们的估计量是绝对准确的,剩下的就是配置\(H\)矩阵加快这个系统收敛到0的速度即可。这就是所谓的状态观测器(State Observer),使用控制框图描述如下所示:
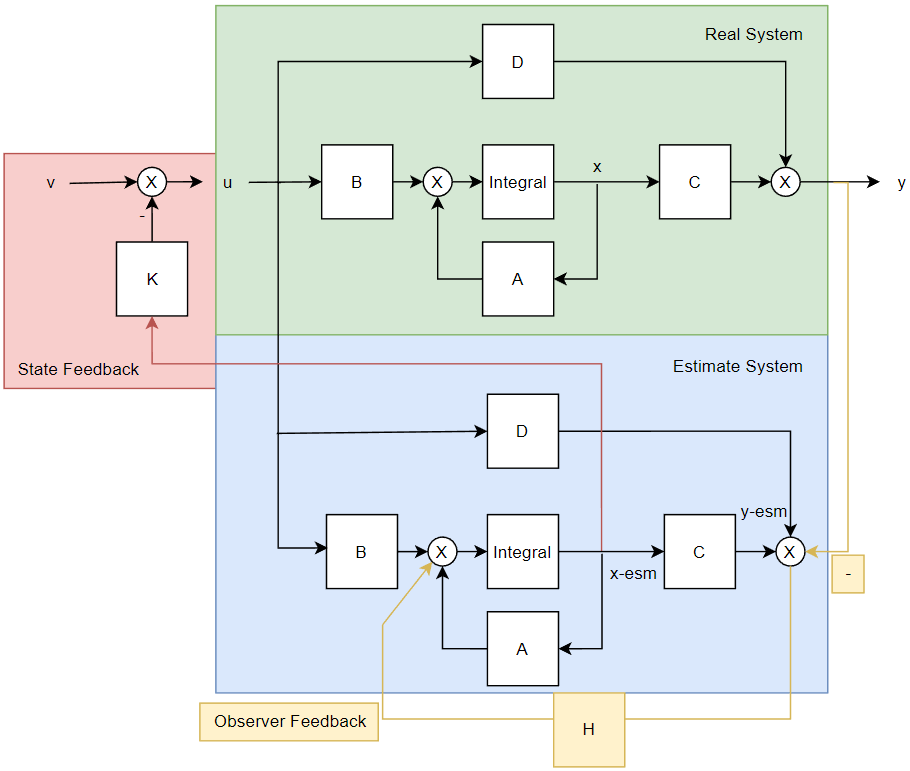
上图描述的就是状态反馈控制器-状态观测器联合控制。绿色部分表示真实系统(Real System)也就是我们实际的控制目标,蓝色部分表示我们”模拟运算“状态变量\(\hat x\)的部分也就是估计系统(Estimate System),二者通过黄色的反馈线将二者的输出结合起来代入估计系统消除估计误差\(e=x-\hat x\)形成一个状态观测器(State Observer),最后将状态估计的结果\(\hat x\)作为生成控制律的依据输入红色的状态反馈(State Feedback)之中进行整体控制。
1.2 面对令人恼火的噪声,我们能做什么
笔者在本科阶段第一次接触到状态观测器时也是惊为天人,觉得这真是世界上最缜密,最精确的观测系统,唯一的担心就是自己的\(A-HC\)参数调节的不好导致误差收敛速度过慢进而导致系统相位裕度减小甚至失去稳定性。但是在实际的工程操作过程中我感到了理论和现实,美好理想和社会毒打之间的差距。这样的状态观测器有几个重要槽点:
- 当我们的模型不甚精确,也就是估计系统和真实系统的\(A,B,C,D\)是对不上号的怎么办呢?毕竟现实工程之中最难的往往不是证明能观能控配置极点,而是辨识系统并且建立足够精确的系统模型。
- 这个世界上不存在完全精确的器件,测量使用的器件可能本身就有偏差,这也是一个需要着重讨论的问题,假设真实值是50,但是我使用的仪器标记的49.5对应真实值的50该怎么办呢?
- 以上一切的分析框架都是基于我们所处理的信号可以用解析的形式表达,可以进行数学分析,但是往往我们在实际工程中碰到的都是随机噪声,解析分析在随机过程面前简直就是驴唇不对马嘴!
有的读者不能够很好的理解随机过程出现在什么地方,事实上还是出在我们建模的不精确,这其实是一件挺奇妙的事情。马克思告诉我们人从世界之中获得感性认识材料,进而到理性认识,进而指导实践,实践又可以获得新的认识……学过一些控制理论的读者可以敏锐的感知到这也是一个闭环系统!实践就是我们的控制律,认识就是我们的观测器——建模不精确其实就是人本身这个闭环系统控制器的观测器不够强大嘛,所以从这个角度来说滤波器解决的是模型不精确估计测量不准确的问题,但是滤波器出现的源头本身就是人类这个闭环系统的观测器不精确……
现在我们首先来讨论噪声的来源和噪声的表现形式:我们通常认为噪声包括两部分也就是系统模型之中本身就携带的过程噪声(Process Noise)以及测量过程之中因为测量手段和仪器引起的测量噪声(Measuring Noise)。还是采用小车的例子来说:
- 假设小车行驶的地面依旧大部分绝对光滑,但是这个光滑的地面本身并不均匀,也就是说在小车形式的过程之中不知道什么时候就会碰到一个不光滑点,这些点的摩擦系数也是不确定的。那么我们这样描述:小车行驶的地面的摩擦系数\(\mu\)是一个随机量,光滑时显然\(\mu=0\)。声明:我知道以下假设很扯淡,但是介于我们在进行理想讨论我认为可以接受。负数的\(\mu\)代表该处地面由于神奇的力量和小车的轮子之间存在一种和运动方向相同的驱动力。总体而言摩擦系数的随机分布符合正太分布,并且数学期望为0。
- 又已知我们测距里的时候使用了超声波测距,由于传感器本身的性能问题、PCB布线之中的干扰问题、系统运行时周遭电磁场的干扰问题、采集设备ADC本身的波动问题导致测得的数据事实上是真实数据叠加了一个正态分布噪声,依旧期望为0。也就是说我们采集的数据事实上带有一定程度的随机型,随机变量符合正态分布,期望为小车位移的真实值。
面对一个正态分布的噪声,最朴素的处理办法就是:已知信号=真实+噪声,故而求取真实值的方式就是信号-噪声,然而在这个办法之中最大的问题是,假设我们这样表达噪声:
$$\tag{1-7}
h(t)=h_{real}(t)+h_{noise}(t),h_{noise}\sim N(\mu,\sigma^2)
$$
我们会发现由于噪声本身是随机的,你根本无法确定你要减去的是些什么东西!那么我们可以试图使用概率与数理统计的方法解决问题,明显这个噪声根据大数定理依概率收敛于期望:
$$\tag{1-8}
\forall \epsilon>0,\lim\limits_{t\to\infty}P\{|h_{noise}-E(h_{noise})|<\epsilon\}=1
$$
那么也就是说假设小车的位置静止不动,我们取测量值若干次,只要样本数量足够大那么噪声叠加起来一定收敛到其期望也就是0——这就是说我们可以采用次朴素的办法:使用多次测量平均值。
$$\tag{1-9}
\hat x=\frac{x_1+x_2+\cdots+x_n}{n}=\frac 1n\sum_{i=1}^nx_i
$$
但是这样带来的问题依旧是很明显的:首先就是我们要记录大量的样本值做平均运算,但是这可以通过一个小小的四则运算来解决,假设我们计算出第\(k\)的估计\(\hat x_k\)我们又有了第\(k+1\)次的测量数据\(x_{k+1}\)那么我们可以这样得出新的估计:
$$\tag{1-10}
\hat x_{k+1}=\frac{k\hat x_k+x_{k+1}}{k+1}
$$
除此之外还有其他难以解决的问题:假设小车现在不是静止的(我们可以认为只要测量的采样频率远远高于小车位置的变化率那么小车就是所谓”静止“的,但是因为经费和技术限制等原因我们不可能无穷的拉高采样频率,这是极其不现实的)那么一旦小车动起来,”历史数据“就会使我们的估计严重失真,例如我们有10000次小车\(x=5\)的数据,然而小车突然动了起来变成了\(x=10\)那么可以预见的是在几千次迭代之前我们不可能获得一个误差更小的位置估计。
一种简单的解决办法是只保留10次或者较少次数的数据以提升估计对于真实位置的跟随灵敏程度,我们且不谈这样就又要保存历史数据并且不一定十分有用的问题——这个保留次数到底该怎么选择?换句话说就是我们面向新的测量数据,我们是更加相信历史估计(更多的保留次数)还是更加相信测量结果(更少的保留次数)呢?
在讨论这个问题之前我们有必要解决一个概念性的但是非常让人迷惑的问题:我们处理的一般是连续时间系统(Continuous-Time System)但是实际写程序的时候往往将控制器或者滤波器写成在循环之中定时迭代的形式也就是离散时间系统(Desicrete-Time System),这就涉及到将观测器/滤波器离散化。我们在处理数值常微分方程(nODE,Numerical Ordinary Differential Equation)的时候常使用欧拉法(Euler Method),让我们考虑这样一个微分方程极其初始条件:
$$\tag{1-11}
\dot y(t)=f[t,y(t)],y|_{t=0}=y_0
$$
针对于\(t=t_k\)时刻的单步我们可以将曲线线性化为一条斜率为\(\dot y_k\)的直线进行处理,这个线性化的范围也就是我们的单步离散时间片的长度,记作\(\Delta t\),那么:
$$\tag{1-12}
y_{k+1}=y_k+\Delta tf(t_k,y_k)
$$
本着这样的思路,我们可以尝试将之前推导的状态观测器进行离散化,将微分方程变成一个离散的差分递推方程,这里的\(y\)是不包含\(Du\)项的也就是\(y=Cx\),这样做是因为直接控制项\(Du\)在实际系统之中十分不常见,并且可以通过简单的减法直接消除,另外我们发现\(Du\)与系统状态不产生耦合,那么分析\(Du\)事实上是一种吃力不讨好的无效行为:
$$\tag{1-13}
\begin{align}
\hat x_{k+1}&=\hat x_k+\Delta t\dot{\hat x_{k}}\\
\dot{\hat x}&=A\hat x+Bu+H(y-C\hat x)\\
\hat x_{k+1}&=\hat x_k+\Delta t[A\hat x_k+Bu_k+H(y_k-C\hat x_k)]\\
&=[I+\Delta t(A-HC)]\hat x_k+\Delta tBu_k+\Delta tHy_k
\end{align}
$$
以上的方法看似已经解决了问题,但事实上一个更加严重的问题因为这种粗暴的线性化暴露了出来,在之前图中提到的蓝色估计系统部分表现完美,但是我们注意到黄色线代表的观测反馈出现相位延迟,当离散化后的反馈校正测量信号\(y_k\)处于\(k\)步时实际计算出来的并不是\(\hat x_k\)而是比这个相位晚一步的\(\hat x_{k+1}\)这一步。显然我们需要将步数对齐,这就引出了”先验估计(priori estimate)“和”后验估计(posteriori estimate)“两个核心概念:先验估计指的是未加入反馈前计算出的离散信号,后验估计指的是加入了同步数的测量反馈校正验证之后的离散信号。我们用\(\hat x_k^-\)来标记先验信号,而后验信号符号则与原来的验证信号相同,那么先验信号和后验信号可以表述为:
$$\tag{1-14}
\begin{align}
\hat x_{k+1}^-&=(I+\Delta tA)\hat x_k+\Delta tBu_k\\
\hat x_{k+1}&=\hat x_{k+1}^- -\Delta tHC\hat x_{k+1}^-+\Delta tHy_{k+1}
\end{align}
$$
需要声明的是,欧拉方法是一种不甚精确,不甚严谨的离散化方案。笔者私以为如果想要好好的进行离散化进行从连续时间系统到离散时间系统或者采样系统的转换,还是需要使用零阶保持器(ZOH)进行严谨的离散化和推导。在这里使用欧拉法进行推导有两个原因:一是因为ZOH并不是本文的重点也和本文的重点没有多大关系,反而有可能劝退读者;二是因为欧拉法简单的实现方法真的十分利于讲清楚先验估计和后验估计有什么区别为什么要存在这一点。
1.3 卡尔曼滤波器到底在干什么
注意:本小节内容建议在下一章节之中详细推导卡尔曼滤波器和卡尔曼增益时反复对照观看,不要在掌握卡尔曼推导过程和状态观测器推导过程之前尝试完全的、彻底的理解,这是不符合学习规律的。如果读者已经掌握了卡尔曼滤波器的推导和应用方法那么可以跳过后续部分,事实上本小节和下图是本文之中笔者自认为最精华的部分。
在完成了连续系统观测器/滤波器的离散化之后,剩下的部分其实就是改造均值滤波器,改造均值滤波器的核心其实就是制定一个策略:在本次估计之中应当更加相信历史数据得出的估计还是更加相信测量数据得到的实时信号?卡尔曼滤波器整体结构图如下所示:
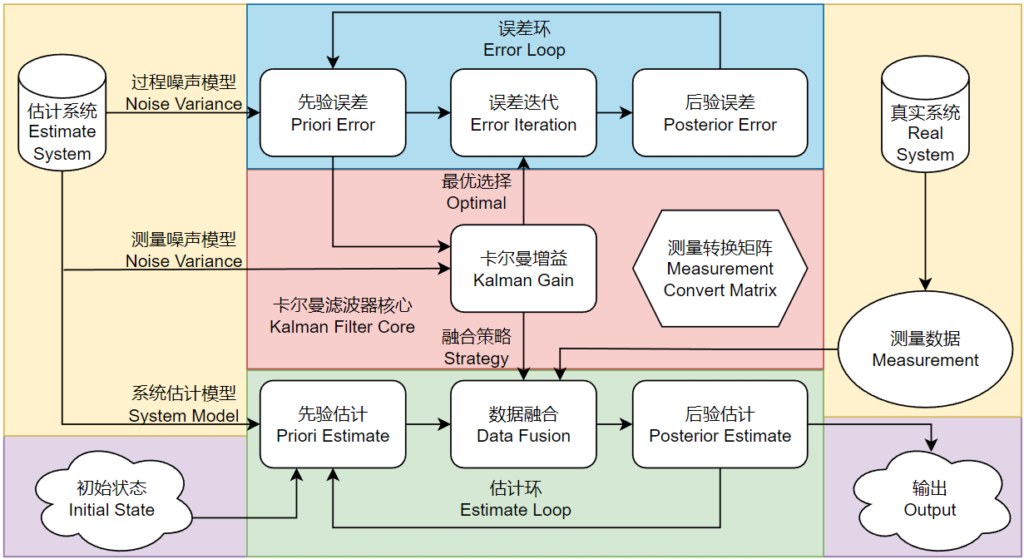
卡尔曼滤波器的核心是卡尔曼增益(Kalman Gain)的动态计算,这个计算将会被用于数据融合之中估计数据与测量数据的权重分配,也就是所谓的融合策略。在数据融合一侧,也就是绿色部分,形成了一个闭环,这个闭环主要负责估计值的计算和校正,同时卡尔曼滤波器输出的估计量也是来源于这个环。而如何计算卡尔曼增益呢?这就要依赖于蓝色部分的误差协方差矩阵迭代运算,这个部分也形成了一个环,这个环保证了误差迭代过程中随机误差始终保持最小的方差(Variance),在已知随机噪声的期望是0的状况下,越小的方差代表了越高的估计准确度,这也就是我们为什么说卡尔曼滤波器是最优的(Optimal)。
卡尔曼滤波器本身和前文提到的状态观测器比较相似,都需要一个真实系统提供测量数据,都需要一个模拟的估计系统进行估计也就是数据预测(Prediction),输出都是经历了测量数据反馈校验的估计值。事实上关于这部分内容可以做一个粗略的概括:
滤波器(Filter)和观测器(Observer)的相同之处在于二者都需要一个模拟系统进行动态估计,也都需要对于真实系统进行数据测量用于校正初始误差或者噪声,也都进行了一定程度的数据融合,也就是某种加权平均的方式将估计数据和校正数据联合计算。
观测器的理论体系之中完全不包含任何随机噪声,也就是说观测器本身的设计目的是收敛的(Convergent)即在没有任何随机噪声的情况能够令估计误差为0。基于这一点观测器的融合策略系数,也就是\(H\)矩阵是一个常数矩阵,是固定的。
滤波器的理论体系是囊括了随机噪声的,并且设计目的之一就是解决在有随机噪声的情况下观测器不可能将估计误差下降到0这一问题。观测器用的是微分方程描述系统,而滤波器使用随机微分方程(Stochastic Differential Equation)进行系统建模,故而其数据融合的策略系数,在卡尔曼滤波器之中也就是卡尔曼增益(Kalman Gain)是动态计算的,用来应对过程高斯噪声和测量高斯噪声(卡尔曼滤波器只能处理高斯噪声,但是不代表所有滤波器都能或者都只能处理高斯噪声)。
二者在系统静态下的稳态精度(Stationary)很难用分析的方法比较出优劣,根据工程经验基本是相同的。但是如果初始值不确定度较大并且含有随机噪声那么二者的精度都会下降;如果初始值的不确定度和噪声的概率分布是已知的,并且滤波器例如卡尔曼这样的能够达到最优估计,那么瞬态精度(Trasient)一定比纯静态的观测器要好得多。
当然也有人从其他的方面说卡尔曼滤波器本质是应用于高斯噪声条件下的最优线性观测器,或者说是一种广义上的里卡蒂(Riccati)观测器,这种分析方法的来源是:观测器要求误差系统矩阵\(A-HC\)的特征值全部位于复平面的左侧,而卡尔曼滤波器事实上相当于解了一个连续里卡蒂方程(Continuous Ricatti Equation)并且这个解提供了李雅普诺夫(Lyapunov)函数,只不过这个解是时变的而已。
2. 卡尔曼滤波器是咋来的——推导
从本章节开始,笔者将对卡尔曼滤波器具体如何离散化实现进行详细推导。虽然从应用的角度而言只要记住几个核心公式,甚至说学会熟练使用GitHub上面的一些开源库也能够应用到工程之中,但是很多初学者甚至认为自己能够熟练使用的工程师实际上并不理解各个参数背后的意义以及选择方法。通过上面的阐述我想我们能够达成这样一种共识:滤波器和观测器虽然设计目的是为了进行参数估计,但是本身也存在闭环结构和动态控制参数——它们本身就是一个小系统,那么就自然有其实现方法和参数选择和调节策略,想要超越”乱调乱试+查表+借鉴“的层面就必须深入底层原理,理解实现。
2.1 理解本文需要的一点数学基础
在推导的过程之中我们主要设计到的部分就是:离散形式下的状态空间表示的系统,高斯(正态)噪声的随机过程与数理统计分析,以及一些的矩阵运算和矩阵求导。对于本小节感到不知所措,不明所以的读者可以先简略后跳过,在后续推导用到相关结论时再反过来查看证明和推导。
2.1.1 数据融合 Data Fusion
让我们这样考虑一个简单的场景:一个小学二年级的学生需要使用直尺测量出一个长度,但是有两个不幸的消息:该小学生手抖,每次使用直尺测量长度时不能够将零刻度线完全的对准线段的起点,这导致他使用直尺测量出的数据之中耦合了一个正态分布的误差;其次是该小学生酷爱劣质文具,这导致了他使用的两把直尺全部不精确,其中一把直尺总是会测量出更长的长度,其中一把直尺总是会测量出更短的长度。而我们需要做的就是:如何选定一个\(k\)值加权的得出一个比两把尺子都更加精确的测量结果?让我们更加精确的使用数学语言来表述,首先我们拿到的两个随机样本是:
$$\tag{2-1}
\begin{align}
X_1 &\sim N(\mu_1,\sigma_1^2)&x_1=X_1(\omega)\\
X_2 &\sim N(\mu_2,\sigma_2^2)&x_2=X_2(\omega)
\end{align}
$$
而对于这两个样本,我们希望使用一个常数\(k\)进行加权平均,同时并不改变均值的量纲大小,那么我们可以这样去描述这个动作:
$$\tag{2-2}
\hat x=(1-k)x_1+kx_2,k\in[0,1]
$$
不难看出这个\(k\)的意义其实就是选择权重,如果\(k=0\)那么就代表我们完全相信\(x_1\)的数据而抛弃\(x_2\)的数据;反之如果\(k=1\)那么就代表我们完全相信\(x_2\)的数据而抛弃\(x_1\)的数据。那么现在的问题就是如何选择\(k\)能够令整个\(\hat x\)的随机误差最小呢?也就是说选择一个\(k\)使得\(\hat x\)的方差最小,首先来求方差,可以看出方差是一个关于\(k\)的二次函数,那么自然可以选取出令方差最小的\(k\):
$$\tag{2-3}
\begin{align}
D\hat X&=D\{(1-k)X_1+kX_2\}=D\{(1-k)X_1\}+D\{kX_2\}\\
&=(1-k)^2DX_1+k^2DX_2=(1-k)^2\sigma_1^2+k^2\sigma_2^2\\
&=(\sigma_1^2+\sigma_2^2)k^2-2\sigma_1^2k+\sigma_1^2\\
\frac{d}{dk}D\hat X&=2(\sigma_1^2+\sigma_2^2)k-2\sigma_1^2\\
\frac{d}{dk}D\hat X&=0\Rightarrow k=\frac{\sigma_1^2}{\sigma_1^2+\sigma_2^2}
\end{align}
$$
求出使方差最小的\(k\)之后将其代入原式可以得到估计值的方差和期望。这里需要说明两点:由于我们的测量数据带入了随机过程,那么我们得到的估计值一定是含有随机过程的,那么就无法在分析意义上达到完全的无误差,只能使误差最小,在同样的无偏估计之中方差最小的无偏估计就是最优的估计,也就是说这种估计犯错误的概率和程度是最小的,因此我们说卡尔曼滤波器是最优(Optimal)的;在下式求出的期望之中读者可能有这样一个疑问:万一这个期望并不等于真实值那么这不就不是一个无偏估计了么?这个认识是对的,但是本方法精妙的一点在于这样的期望和真实值之间的差距事实上已经不包含随机过程了,我们可以直接在结果之中减去这个误差,这只改变期望而不改变方差,减去了这个误差之后得到的就是最优的无偏估计,也就是说我们完成了数据融合(Data Fusion)。求取方差和期望如下:
$$\tag{2-4}
\begin{align}
D\hat X&=\frac{\sigma_1^4}{\sigma_1^2+\sigma_2^2}-\frac{2\sigma_1^4}{\sigma_1^2+\sigma_2^2}+\frac{\sigma_1^2(\sigma_1^2+\sigma_2^2)}{\sigma_1^2+\sigma_2^2}
\\&=\frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2}\\
E\hat X&=E\{(1-k)X_1+kX_2\}=(1-k)EX_1+kEX_2\\
&=\frac{\mu_1\sigma_2^2+\mu_2\sigma_1^2}{\sigma_1^2+\sigma_2^2}
\end{align}
$$
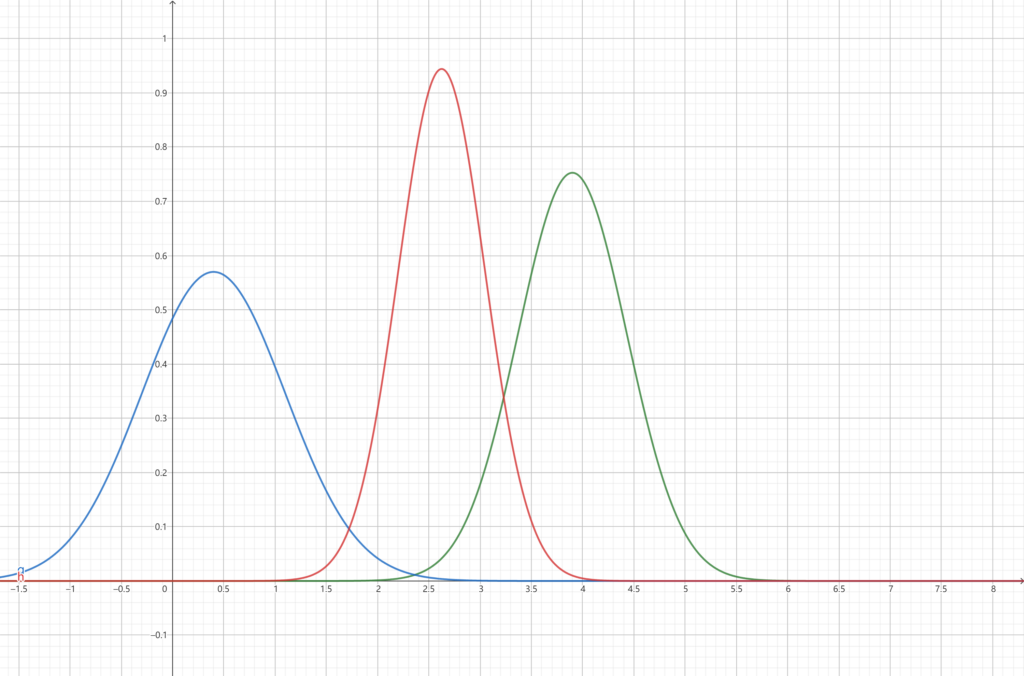
如上图所示,蓝色曲线表示\(X_1\)的概率密度,绿色曲线表示\(X_2\)的概率密度,红色曲线表示融合后的\(\hat X\)的概率密度。通过图像很容易的发现这个融合使得估计数据的方差小于两个原始数据的方差,期望介于二者之间。笔者使用GeoGebra这款工具完成了这一图像,感兴趣的读者可以打开相关链接尝试一下工具,模拟计算使用的模型文件可以在这里下载。
2.1.2 多维正态随机变量与协方差矩阵 Covariance Matrix
凡有高中数学基础的读者都能够理解什么是正态分布,学过概率论与数理统计的同学可能对二维随机变量的联合正态分布也有了解。但是我们在推导卡尔曼滤波器的过程中面对的是这样一个问题:我们的系统可能存在\(n\)阶状态变量,也就是说噪声可能分布在每一个状态变量上,并且各个状态变量的噪声之间可能不独立并且相关,那么如何描述这些随机变量的联合正态分布,如何求取这个联合正态分布的随机分散状况呢?让我们假设有这样一系列随机变量,并且使用向量表示:
$$\tag{2-5}
\begin{cases}
X_1\sim N(\mu_1,\sigma_1^2)\\
X_2\sim N(\mu_2,\sigma_2^2)\\
\vdots\\
X_n\sim N(\mu_n,\sigma_n^2)\\
\end{cases}\Rightarrow X=
\begin{bmatrix}
X_1\\X_2\\\vdots\\X_n
\end{bmatrix},P=\begin{bmatrix}\mu_1\\\mu_2\\\vdots\\\mu_n\end{bmatrix}\Rightarrow
X\sim N(P,?)
$$
我们注意到,各个随机变量的均值显然也可以写成一个向量,就称作期望向量,完全可以用来描述这个随机变量向量的期望,那么如何描述它们的方差呢?如果粗暴的写一个\(n\times 1\)维向量想染是不正确的,因为这就意味着我们粗暴的认为任意两个随机变量之间没有相关性。所以我们使用如下一个矩阵去描述他们的概率分布离散度的状况和相关性:
$$\tag{2-6}
Q=\begin{bmatrix}
DX_1&Cov(X_1,X_2)&\cdots&Cov(X_1,X_n)\\
Cov(X_2,X_1)&DX_2&\cdots&Cov(X_2,X_n)\\
\vdots&\vdots&\ddots&\vdots\\
Cov(X_n,X_1)&Cov(X_n,X_2)&\cdots&DX_n
\end{bmatrix}
$$
我们建立这样一个协方差矩阵(Covariance Matrix)去描述他们的离散程度和相关性,我们假定其中任意两个随机变量都具有相关性(如果没有相关性只不过是协方差为0),然后用矩阵元素\(Q_{ij}\)去描述随机变量\(X_i,X_j\)之间的协方差也就是\(Cov(X_i,X_j)\),特别地如果\(i=j\),也就是对角线上的元素,描述的是随机变量和自己的协方差矩阵,那么当然也就是它自己的方差。不难注意到,由于协方差具有可交换性,也就是\(Cov(X_i,X_j)=Cov(X_j,X_i)\)这个矩阵显然是一个对称矩阵也就是\(Q=Q^T\)请注意这个重要的性质;并且由于方差本身一定\(\ge0\)那么就是说这个矩阵的主对角线半正定,也就是说当我们求取这个矩阵的迹\(tr(Q)\)的最小值,就会使这些随机变量的方差本身趋向于最小。那么基于协方差矩阵和期望向量我们可以说这个随机变量向量服从正态分布:
$$\tag{2-7}
X\sim N(P,Q)
$$
但是我们再次注意到,假设我们有\(n\)阶系统,这就意味着我们要求出协方差矩阵就要计算\(\frac12(n^2+n)\)个协方差(方差),这对于在嵌入式设备和控制器上进行噪声建模是一个极其繁重的工作,于是我们需要一种简便的计算协方差矩阵的方式,这样也便于我们进行后续的推导。首先我们回顾一下协方差的矩求法,并且我们假设随机变量\(X_i\)的样本大小为\(m\)个:
$$\tag{2-8}
\begin{align}
Cov(X_i,X_j)&=E\{(X_i-EX_i)(X_j-EX_j)\}\\&=\frac1m\sum_{k=1}^m(x_{ik}-EX_i)(x_{jk}-EX_j)
\end{align}
$$
我们注意到若干次这种运算实际上可以使用一种更加统一的表达方法,那么我们考虑使用一种矩阵运算去完成这种运算,首先我们明确一下\(X\)这个向量的元素是一个随机变量,在统计学之中这个随机变量本身可以写成其所有的样本构成的一个向量,那么\(X\)的矩阵表达形式为:
$$\tag{2-9}
\begin{align}
X_i&=\begin{bmatrix}x_{i1}&x_{i2}&\cdots&x_{im}\end{bmatrix}\\
X&=\begin{bmatrix}X_1&X_2&\cdots&X_n\end{bmatrix}=\{x_{ij}\}_{n\times m}\\
&=\begin{bmatrix}
x_{11}&x_{12}&\cdots&x_{1m}\\
x_{21}&x_{22}&\cdots&x_{2m}\\
\vdots&\vdots&\ddots&\vdots\\
x_{n1}&x_{n2}&\cdots&x_{nm}
\end{bmatrix}
\end{align}
$$
得到上述矩阵的内容之后,为了构造\(X_i-EX_i\)我们需要一个辅助矩阵来描述这个变量,并且使用这个辅助矩阵的对称相乘来计算出两个变量的二阶中心矩,也就是所谓的协方差。下面我们来构造这个辅助矩阵\(M\):
$$\tag{2-10}
\begin{align}
M&=X-\frac1mX\{1\}_{m\times m}\\
&=\begin{bmatrix}X_1\\X_2\\\vdots\\X_n\end{bmatrix}-\frac1m\begin{bmatrix}X_1\\X_2\\\vdots\\X_n\end{bmatrix}
\begin{bmatrix}1&1&\cdots&1\\1&1&\cdots&1\\\vdots&\vdots&\ddots&\vdots\\1&1&\cdots&1\end{bmatrix}_{m\times m}=\begin{bmatrix}X_1-\{EX_1\}_{1\times m}
\\X_2-\{EX_2\}_{1\times m}\\\vdots\\X_n-\{EX_n\}_{1\times m}
\end{bmatrix}\\&=
\begin{bmatrix}
x_{11}-EX_1&x_{12}-EX_1&\cdots&x_{1m}-EX_1\\
x_{21}-EX_2&x_{22}-EX_2&\cdots&x_{2m}-EX_2\\
\vdots&\vdots&\ddots&\vdots\\
x_{n1}-EX_n&x_{n2}-EX_n&\cdots&x_{nm}-EX_n
\end{bmatrix}
\end{align}
$$
随后我们不难想到,这个二阶中心矩运算可以转化为这个辅助矩阵与自己的转置相乘,并且对样本个数取平均数即可得到协方差矩阵,也就是:、
$$\tag{2-11}
Q=\frac1mMM^T
$$
这里需要强调的是,假设我们认为所有随机变量都是一个理想的高斯噪声,也就是\(X_i\sim N(0, \sigma_i^2)\)的话,那么辅助矩阵和计算形式可以变得更加简单:
$$\tag{2-12}
\begin{align}
X_i&\sim N(0,\sigma_i^2)\\
Cov(X_i,X_j)&=E\{(X_i-EX_i)(X_j-EX_j)\}=E\{X_iX_j\}\\
M&=X\\
Q&=\frac1mMM^T=E\{XX^T\}
\end{align}
$$
2.1.3 关于矩阵的迹(标量)对于矩阵求导的两个重要结论
在上一章节的阐述和本章节数据融合的内容之中我们可以发现,在获得最优估计量的过程之中需要使得噪声的方差最小,也就是噪声协方差矩阵的迹最小,迹是一个标量而我们的策略系数也就是卡尔曼增益应当是一个数值矩阵(多维度状态变量),那么就涉及到如何选择矩阵使得一个标量最小——求导获取极值点是一个通用的办法,这里主要讨论要用到的两种情况,默认所有矩阵为\(n\)阶方阵:
- 对于矩阵的迹\(tr(AB)\)求关于矩阵\(A\)的导数
$$\tag{2-13}
\begin{align}
C&=AB\Rightarrow C_{ij}=\sum_{k=1}^nA_{ik}B_{kj}\\
tr(C)&=\sum_{t=1}^nC_{tt}=\sum_{i=1}^n\sum_{j=1}^nA_{ij}B_{ji}\\
D&=\frac{d}{dA}tr(C)\\
D_{ij}&=\frac{\partial}{\partial A_{ij}}
\left[\sum_{i=1}^n\sum_{j=1}^nA_{ij}B_{ji}\right]=\sum_{i=1}^n\sum_{j=1}^n\frac{\partial}{\partial A_{ij}}\left[A_{ij}B_{ji}\right]=B_{ji}\\
D&=\frac{d}{dA}tr(AB)=B^T
\end{align}
$$ - 对于矩阵的迹\(tr(ABA^T)\)求关于矩阵\(A\)的导数
$$\tag{2-14}
\begin{align}
C&=ABA^T=DA^T\\
D_{ij}&=\sum_{k=1}^nA_{ik}B_{kj}\\
C_{ij}&=\sum_{t=1}^nD_{it}A^T_{tj}=\sum_{t=1}^nD_{it}A_{jt}=\sum_{t=1}^nA_{jt}\sum_{k=1}^nA_{ik}B_{kt}\\
E&=\frac{d}{dA}tr(C)\\
E_{ij}&=\frac{\partial}{\partial A_{ij}}\sum_{u=1}^nC_{uu}=\frac{\partial}{\partial A_{ij}}\sum_{u=1}^n\left[\sum_{t=1}^nD_{ut}A_{ut}\right]\\
&=\frac{\partial}{\partial A_{ij}}\sum_{u=1}^n\left\{\sum_{t=1}^nA_{ut}
\left[\sum_{k=1}^nA_{uk}B_{kt}\right]\right\}\\
&=\frac{\partial}{\partial A_{ij}}\sum_{u=1}^n\sum_{t=1}^n\sum_{k=1}^nA_{ut}A_{uk}B_{kt}=\frac{\partial}{\partial A_{ij}}\sum_{t=1}^n\sum_{k=1}^nA_{it}A_{ik}B_{kt}\\
&=\frac{\partial}{\partial A_{ij}}\left[\sum_{t=1,t\ne j}^n\sum_{k=1}^nA_{it}A_{ik}B_{kt}+A_{ij}\left(\sum_{k=1,k\ne j}^nA_{ik}B_{kj}+A_{ij}B_{jj}\right)\right]\\
&=\sum_{t=1,t\ne j}^nA_{it}B_{jt}+\sum_{k=1,k\ne j}^nA_{ik}B_{kj}+2A_{ij}B_{jj}\\
&=\sum_{t=1}^nA_{it}B^T_{tj}+\sum_{k=1}^nA_{ik}B_{kj}\\
E&=\frac{d}{dA}tr(ABA^T)=AB^T+AB
\end{align}
$$
这似乎是一个较为复杂的任务,事实上最便捷的解法需要使用矩阵分析之中的某些结论,然而使用线性代数和矩阵的基本知识也不难解出。我们对这两个任务都采取首先将目标求迹矩阵元素展开,表示为单纯的数值组合的形式,而后对目标求导矩阵的每个元素求偏导,最后组合到结果矩阵之中,这部分非常基础但是比较枯燥。
2.2 回归到一些基本的问题
前文提到,状态观测器能够处理不计入随机噪声的系统之中无偏状态估计的问题,滤波器则主要解决含有随机噪声系统之中状态估计的问题,首先我们需要对含有随机噪声的系统进行一般性的建模,也就是将过程噪声和测量噪声代入其中:
$$\tag{2-15}
\begin{cases}
\dot x&=Ax+Bu+\omega\\
y &= Cx+Du+\nu
\end{cases}
$$
上式的基础是式(1-3)之中提到的状态空间表述的一般性线性控制系统(卡尔曼主要处理线性系统的高斯噪声,非线性系统的高斯噪声通过扩展卡尔曼滤波器(Extended Kalman Filter)处理,卡尔曼滤波器无法处理非高斯噪声,关于扩展卡尔曼滤波器的内容将在下一章节之中简述),在此基础上我们认为系统之内有一个随机噪声\(\omega\),而系统的输出过程之中有另一个随机噪声\(\nu\)。考虑到:
- 直接输出支路\(Du\)不常见并且这部分输出实际上根本没有进入系统和状态变量发生关系,因此这部分内容在测量过程之中毫无意义
- 我们不能假定我们能够直接获取到\(x\)状态变量,这是一种”作弊“行为,因为现实系统之中基本不可能直接获取到\(x\),所以实际上输出矩阵\(C\)是被我们作为测量元器件”复用“了
基于上述考虑,我们忽略掉系统之中的\(Du\)项,并且用一个测量元件抽象出的矩阵\(H\)来表示测量环节,从而替换掉矩阵\(C\),这样可以使得概念更加清晰,但是在实际操作之中并不代表我们不可以继续复用矩阵\(C\)。我们现在将系统进行离散化,但是为了推导过程感观上的良好仍然使用原来的字母,但是读者需要明确的是,当我们从连续时间系统离散化的时候仍旧需要按照上文中式(1-10)至式(1-13)的部分或者其他的什么方法进行离散化。考虑随机噪声的离散系统如下所示:
$$\tag{2-16}
\begin{cases}
x_k&=Ax_{k-1}+Bu_{k-1}+\omega_{k-1}\\
z_k&=Hx_k+\nu_k
\end{cases}
$$
这就是叠加了随机噪声的系统模型,由于我们进行了离散化又考虑了相位滞后问题,可见系统本身的方程是从\(k-1\)步迭代到\(k\)步,而测量方程就是同步的——这也就是说第一个方程应当用于先验估计的产生,是所谓的”数据A“;第二个方程应当用于后验估计的修正,也就是所谓的”数据B“,使用这两把都不精确的尺子得出的数据进行数据融合我们得到后验估计。上式之中的\(\omega,\nu\)都是多维随机噪声向量,他们的分布根据我们在2.1.2小节之中的推导可以表述为:
$$\tag{2-17}
\begin{align}
\omega&\sim N(0,Q),&Q=E\{\omega\omega^T\}\\
\nu&\sim N(0,R),&R=E\{\nu\nu^T\}
\end{align}
$$
构建观测器的经验告诉我们我们需要构建一个模拟系统用于估计状态变量,并且有一个模拟的输出方程用于和实际输出做对比,在这里的推导之中输出方程就是测量方程。然而我们通过分析的方法还是无法表示随机噪声,因此我们的模拟系统和测量模型方程都是不精确的。故而我们设定两个变量:
- \(\hat x_k^-\)符号表示我们通过不精确的模拟系统推测迭代得出的第\(k\)次先验估计量,但是这个估计量的得出并不是基于上一次的先验估计,这样的话误差不断累积是非常恶劣的情况;我们需要将上次滤波器后验估计的值当作上次系统的真实值得到这次的先验估计。
- \(\hat x_k^m\)符号表示我们得到了测量数据\(z_k\)后根据不精确的测量方程反演得出的第\(k\)次状态变量测量值的估计值。
$$\tag{2-18}
\begin{align}
\hat x_k^-&=A\hat x_{k-}+Bu_{k-1}\\
z_k&=H\hat x_k^m
\end{align}
$$
现在我们得到了两个数据源,一个是我们通过模拟系统推测估计得到的先验估计数据,另一个是我们根据实际测量数据反演得到的测量估计数据。我们应当明确:前者事实上叠加了过程噪声,后者则叠加了测量噪声,于是我们已经得到了两把不准确的尺子。我们的目的就是根据两把不准确的尺子按照2.1.1小节之中数据融合的方式得到一把更加精确的尺子,也就是后验估计\(\hat x_k\),我们假设我们融合数据时用到的加权常数(这里因为考虑多维变量故而是一个常数矩阵)为矩阵\(G\)那么就有融合校正方程:
$$\tag{2-19}
\hat x_k=(I-G)\hat x_k^-+G\hat x_k^m=\hat x_k^-+G(\hat x_k^m-\hat x_k^-)
$$
而我们注意到,反演过程需要\(\hat x_k^m=H^{-1}z_k\),这里我们不需要考虑\(H\)不可逆的状况,因为如果矩阵不可逆我们根本不可能从测量数据之中推测出真实数据,也就是失去了第二把尺子,那么整个滤波器就没有存在的意义了。但是通用的计算矩阵的逆的方法(一、二阶矩阵的特殊性没有代表性)是计算出矩阵的行列式值和伴随矩阵后得到的,这样的计算方法过于消耗算力资源,并且也不利于我们后续推导的直观性——我们假设矩阵\(G\)具有形式\(G=K_kH\),其中的\(K_k\)就表示卡尔曼增益(Kalman Gain)常数构成的矩阵,那么融合方程可以重写为:
$$\tag{2-20}
\begin{align}
\hat x_k&=\hat x_k^-+K_kH(\hat x_k^m-\hat x_k^-)\\
&=\hat x_k^-+K_k(z_k-H\hat x_k^-)
\end{align}
$$
这就是卡尔曼滤波器的融合方程,对比这个方程和第一章节之中谈到的观测器我们可以发现这样写增益矩阵之后有了一个非常清晰的表述:后验估计即在先验估计的基础上,使用策略\(K_k\)代入测量数据与估计数据的差异进行校正!那么接下来的任务十分清晰:选择合适的\(K_k\)让后验估计与系统真实状态量的随机误差降低到最小——我们就得到了最优估计!
2.3 卡尔曼增益如何使滤波器达到最优估计
首先明确一下我们的目的:让后验估计与系统真实状态量的随机误差降到最小——这里还是需要回顾一下数据融合的内容,假设我们的后验估计不是系统的真实状态量的无偏估计怎么办?也就是说二者期望不一致,那么这个时候直接加上或者减去期望的差距即可,滤波器解决的不是静差,是随机误差。并且更加重要的是:在理想的状况下——也就是系统不包含噪声的模型是精确的状况下估计确实是无偏估计,这一点将在下面证明。目前我们首先考虑定义一个变量表示我们估计的误差:
$$\tag{2-21}
e_k=x_k-\hat x_k
$$
得到了误差定义之后,我们将式(2-20)以及(2-18)和(2-16)的系统迭代方程代入,即可获得误差的结构并且可以发现这个误差的期望为0,这也就是说卡尔曼滤波器的估计的确是一个无偏估计,当然这是要求系统建模完全精确,初始状态设置准确的理想状况:
$$\tag{2-22}
\begin{align}
e_k&=x_k-[\hat x_k^-+K_k(z_k-Hx_k^-)]\\
&=x_k-[\hat x_k^-+K_k(Hx_k+\nu_k-Hx_k^-)]\\
&=(I-K_kH)(x_k-\hat x_k^-)+K_k\nu_k\\
\end{align}
$$
注意到,上式之中由两部分构成,第二部分是测量噪声,这表征了滤波器校正部分带来的随机误差;我们将第一部分之中的\(x_k-\hat x_k^-\)作为一个单独的变量处理,称为先验误差:
$$\tag{2-23}
\begin{align}
e_k^-&=x_k-\hat x_k^-\\
&=(Ax_{k-1}+Bu_{k-1}+\omega_{k-1})-(A\hat x_{k-1}+Bu_{k-1})\\
&=A(x_{k-1}-\hat x_{k-1})+\omega_{k-1}\\
&=Ae_{k-1}+\omega_{k-1}
\end{align}
$$
通过上式推导我们能够发现先验误差也取决于两部分:即系统上一步的后验误差和系统过程噪声,这表征了滤波器估计部分带来的随机误差,我们可以从上式中知道这样两件事情:
- 系统输入\(Bu\)事实上与滤波器的误差无关,也就是滤波器的设计过程完全不会被输入影响也完全不会影响输入的控制律起作用——有现代控制理论基础的读者应当立即反映出这是在设计状态反馈和状态观测器时提到的分离定律在滤波器上的表现
- 系统过程噪声\(\omega_{k-1}\)影响的是\(e_k^-,e_k\)而不是\(e_{k-1}^-,e_{k-1}\),这就说明系统过程噪声和滤波器误差从统计学上来说是独立的,这是一个重要结论!
在明确了滤波器的误差结构后我们可以继续对滤波器误差的数理统计数字特征进行分析,目的是验证误差是否期望为0也就是滤波器输出的估计值是否是系统状态的无偏估计;并且探究误差的协方差矩阵进而找到最小方差对应的滤波器增益\(K_k\):
$$\tag{2-24}
\begin{align}
E(e_k)&=E\{(I-K_kH)ek^-+K_k\nu_k\}\\
&=(I-K_kH)E(e_k^-)+K_kE(\nu_k)\\
&=(I-K_kH)E\{A(e_{k-1})+\omega_{k-1}\}\\
&=(I-K_kH)AE(e_{k-1})\\
&=\cdots\\
&=\left[\prod_{t=1}^k(I-K_tH)A\right]E(e_0)\\
&=\left[\prod_{t=1}^k(I-K_tH)A\right](x_0-\hat x_0)
\end{align}
$$
上式得到就是滤波器在对系统精确建模的情况下得到的误差期望,可以发现误差期望事实上是一个递推/递归(这主要取决于你计算的方式)的表达式,并且其递归过程将会在滤波器设置的模拟系统初始状态之中结束计算,因此只要初始状态精确也就是\(x_0-\hat x_0=0\),那么滤波器的误差期望为0也就是说滤波器输出的后验估计事实上是真实状态变量的一个无偏估计。
在此基础上考虑到误差值中仅仅耦合了过程噪声和测量噪声,并且这两个噪声独立且服从各自的正态分布,我们可以说滤波器的先验误差和后验误差一定也符合正态分布,这个结论可以表达为下式,其中的矩阵\(M_k,M_k^-\)表示的是误差的协方差矩阵,并且因为误差和两个不变的噪声(如果两个噪声是时变的并且符合正态分布,当然这种状况极其少见,那么\(Q,R\)也需要动态计算)不同,是动态变化的,所以他们的协方差矩阵需要跟随系统步数\(k\)动态运算:
$$\tag{2-25}
\begin{align}
e_k&\sim N(0,M_k), &M_k=E\{e_ke_k^T\}\\
e_k^-&\sim N(0,M_k^-), &M_k^-=E\{e_k^-e_k^{-T}\}
\end{align}
$$
获得了误差信号的概率分布协方差矩阵后,我们的思路就更加明确了:在确定误差期望是0的状况下,只要保证误差各个维度上的方差尽量小就可以获得最优的估计精度,在此精度下生效的增益矩阵\(K_k\)就是我们的求取目标,所以我们首先对M进行展开,考虑到之前的推导:
$$\tag{2-26}
\begin{align}
M_k&=E\{e_ke_k^T\}\\
e_k&=(I-KkH)e_k^- -K_k\nu_k\\
M_k&=E\{[(I-K_kH)e_k^–K_k\nu_k][(I-K_kH)e_k^–K_k\nu_k]^T\}\\
&=E\{[(I-K_kH)e_k^–K_k\nu_k][e_k^{-T}(I-K_kH)^T-v_k^TK_k^T]\}\\
&=E\{(I-K_kH)e_k^-e_k^{-T}(I-K_kH)^T\\&\quad\quad-(I-K_kH)e_k^-\nu_k^TK_k^T-K_k\nu_ke_k^{-T}(I-K_kH)^T+K_k\nu_k\nu_k^TK_k^T\}\\
&=(I-K_kH)E\{e_k^-e_k^{-T}\}(I-K_kH)^T-(I-K_kH)E\{e_k^-\nu_k^T\}K_k^T\\&\quad\quad-K_kE\{\nu_ke_k^{-T}\}(I-K_kH)^T+K_kE\{\nu_k\nu_k^T\}K_k^T\\
\end{align}
$$
对于上式之中求出的第一项和最后一项已经在前文之中出现过定义,而在前文的式(2-22)与(2-23)之中我们注意到先验误差\(e_k^-\)与测量噪声\(\nu_k\)是独立的,它们之间没有耦合关系,故而第二项和第三项之中的期望可以进行拆分,并且计算出来,最终得到\(M_k\)的化简表达式:
$$\tag{2-27}
\begin{align}
E\{e_k^-\nu_k^T\}&=E(e_k^-)E(\nu_k^T)=E(e_k^-)\times0=0\\
E\{\nu_ke_k^{-T}\}&=E(\nu_k)E(e_k^{-T})=0\times E(e_k^{-T})=0\\
E\{e_k^-e_k^{-T}\}&=M_k^-\\
E\{\nu_k\nu_k^T\}&=R\\
M_k&=(I-K_kH)M_k^-(I-K_kH)^T+K_kRK_k^T
\end{align}
$$
接下来就是求出\(M_k\)的迹,因为\(M_k\)协方差矩阵,而其对角线元素就是各个维度上的噪声的方差——非对角线表达式是各个维度噪声之间的相关性,各个维度之间噪声的耦合程度我们是不关心的,我们关心的只有所有的单个维度上的噪声强度。而因为方差一定是\(\ge0\)的数,所以求得其迹的最小值对应的\(K_k\)就是求出其所有方差共同最小的值对应的\(K_k\):
$$\tag{2-28}
\begin{align}
tr(M_k)&=tr\{(I-K_kH)M_k^-(I-K_kH)^T+K_kRK_k^T\}\\
&=tr[(I-K_kH)M_k^-(I-K_kH)^T]+tr(K_kRK_k^T)\\
&=tr(M_k^-)-tr(M_k^-H^TK_k^T)-tr(K_kHM_k^-)\\&\quad\quad+tr(K_kHM_k^-H^TK_k^T)+tr(K_kRK_k^T)\\
&=tr(M_k^-)-tr(K_kHM_k^{-T})-tr(K_kHM_k^-)\\&\quad\quad+tr(K_kHM_k^-H^TK_k^T)+tr(K_kRK_k^T)\\
\end{align}
$$
获得了\(M_k^-\)的迹的表达式之后下一步就是使用这个迹对于\(K_k\)求导,导数为0的点就是极值点,而通过前文数据融合的内容不难发现,这个极值点就是最小值点,在该点的\(K_k\)就是滤波器获得最优估计的增益常数矩阵,灵活利用\(M_k^-,R\)作为协方差矩阵是对称矩阵的特性:
$$\tag{2-29}
\begin{align}
\frac{d\,tr(M_k)}{dK_k}&=\frac{d\,tr(M_k^-)}{dK_k}-\frac{d\,tr(K_kHM_k^{-T})}{dK_k}-\frac{d\,tr(K_kHM_k^-)}{dK_k}\\&\quad\quad+\frac{d\,tr(K_kHM_k^-H^TK_k^T)}{dK_k}+\frac{d\,tr(K_kRK_k^T)}{dK_k}\\
&=0-(HM_k^{-T})^T-(HM_k^-)^T\\&\quad\quad+K_k(HM_k^-H^T )+K_k(HM_k^-H^T)^T+K_kR+K_kR^T\\
&=-2M_k^-H^T+2K_k(HM^-_kH^T+R)\\
\frac{d\,tr(M_k)}{dK_k}&=0\Rightarrow M_k^-H^T=K_k(HM^-_kH^T+R)\\
\end{align}
$$
于是我们就可以得到卡尔曼滤波器使估计误差不确定度(uncertainty)最小时的数据融合策略常数矩阵——卡尔曼增益矩阵\(K_k\)的取值,也就实现了合理选择卡尔曼增益使得滤波器实现最优化,这就是卡尔曼滤波器的核心:
$$\tag{2-30}
K_k=\frac{M_k^-H^T}{HM^-_kH^T+R}=M_k^-H^T(HM^-_kH^T+R)^{-1}
$$
通过分析\(K_k\)的取值我们可以发现虽然形式上复杂了不少,但是实际上仍然没有脱离加权平均的框架:当测量噪声也就是测量数据的可信度\(R\)非常小的时候,整体的\(K_k\)趋向于\(H^{-1}\)代入式(2-20)即可发现这时候我们倾向于完全相信测量值;而\(R\)极大也就是测量噪声非常大测量器件的可信度极低的时候,\(K_k\)趋向于0矩阵,这时候我们倾向于完全相信估计值。
2.4 五个方程的迭代游戏
一句话概括卡尔曼滤波器就是:线性最优递归估计算法(Linear Optimal Recursive Estimate Algorithm),其中线性指的是卡尔曼作用于线性系统,最优的问题我们在上一章节进行了详细的证明,而估计是滤波器/观测器的核心概念,那么如何体现其中的递归(Recursive)?我们看到前文进行推导时无论是误差、矩阵、增益几乎都带有一个下标\(k\),这就代表在一个离散时间系统之中这些变量或者常量是要根据系统步数\(k\)动态迭代的。我们发现往往\(k\)步的数据依赖于\(k-1\)步的数据生成,那么只要定义好初始数据也就是\(k=0\)就可以获得任意步数的数据——冗长的递归链在动力学控制系统或者其他什么实时性较高的系统之中是会带来相当可怕的相位延迟的,因此虽然算法是递归定义的,但是通常我们采用递推的方法进行实现。因此卡尔曼滤波器算法的实现共分为两个阶段和五个计算方程,这也就是我们通常说的卡尔曼五个核心公式:
- 预测阶段-先验估计:按照式(2-18)利用上一次的后验估计、系统输入和模型计算:
$$\tag{2-31}
\hat x_k^-=A\hat x_{k-1}+Bu_{k-1}
$$ - 预测阶段-先验误差:在求取先验误差的协方差矩阵时我们采用式(2-25)的方法仿照后验误差协方差矩阵的求法,并且考虑到式(2-23)的第二个重要结论注意到先验误差和过程噪声无关,则可得:
$$\tag{2-32}
\begin{align}
M_k^-&=E\{e_k^-e_k^{-T}\}=\{(Ae_{k-1}+\omega_{k-1})(Ae_{k-1}+\omega_{k-1})^T\}\\
&=E\{Ae_{k-1}e_{k-1}^{T}A^T+Ae_{k-1}\omega^T_{k-1}+\omega_{k-1}e_{k-1}^{T}A^T+\omega_{k-1}\omega_{k-1}^T\}\\
&=AE\{e_{k-1}e_{k-1}^{T}\}A^T+AE(e_{k-1})E(\omega_{k-1}^T)+E(\omega_{k-1})E(e_{k-1}^{T})A^T\\&\quad+E\{\omega_{k-1}\omega_{k-1}^T\}\\
&=AM_{k-1}A^T+Q
\end{align}
$$ - 校正阶段-增益确定:利用先验误差协方差计算出本次迭代的卡尔曼增益矩阵:
$$\tag{2-33}
K_k=\frac{M_k^-H^T}{HM^-_kH^T+R}=M_k^-H^T(HM^-_kH^T+R)^{-1}
$$ - 校正阶段-后验估计:将增益代入数据融合也就是式(2-20)得到滤波器输出的后验估计量:
$$\tag{2-34}
\begin{align}
\hat x_k&=\hat x_k^-+K_k(z_k-H\hat x_k^-)
\end{align}
$$ - 校正阶段-后验误差:将卡尔曼增益矩阵\(K_k\)代入式(2-27)计算本次的后验误差协方差矩阵,为下一步迭代做准备:
$$\tag{2-35}
\begin{align}
M_k&=(I-K_kH)M^-_k(I-K_kH)^T+K_kRK_k^T\\
&=(M_k^- -K_kHM_k^-)(I-H^TK_k^T)+K_kRK_k^T\\
&=(I-K_kH)M_k^- -M_k^-H^TK_k^T+K_k(HM_k^-H+R)K_k^T\\
&=(I-K_kH)M_k^-
\end{align}
$$
3. 扩展卡尔曼滤波器
我们以上所有的讨论都是基于系统完全线性去讨论的,但是在现实工程之中没有任何系统是绝对线性的,反而大部分系统具有非线性甚至时变特征,例如道理摆、平衡车、四旋翼无人机、民航飞机控制系统等等。这个时候卡尔曼滤波器线性+高斯噪声的条件就不满足了,那么扩展卡尔曼滤波器(Extended Kalman Filter)就给我们提供了一些解决思路,首先我们需要先取得系统的线性化不精确模型。
3.1 一点线性化的小技巧
扩展卡尔曼滤波器主要使用泰勒展开(Taylor)去处理系统将其线性化,而非更加彻底的使用微分同胚变换直接更改状态空间拓扑结构的反馈线性化(Feedback Linearization)去做这件事情。众所周知,泰勒展开是将非线性函数分解为若干个幂级数的叠加(这里不讨论余项问题),假设函数在\(t_0\)处展开:
$$\tag{3-1}
f(t)=f(t_0)+f'(t_0)(t-t_0)+\frac{f”(t_0)}2(t-t_0)^2+\cdots+\frac{f^{(n)}(t_0)}{n!}(t-t_0)^n
$$
这里有一个展开点的问题,在控制系统之中我们一般称展开点为工作点(Operation Point),对于许多粗暴的线性展开方案,这个点干脆取在系统的平衡点(Balance Point)例如平衡车或者道理摆通常将\(0^\circ\) 作为展开点,将展开点附近的\(\sin\theta\)认为是0或者\(\theta\),将\(\cos\theta\)认为是1……我们需要明确的是线性化展开事实上只能展开到一阶,因为从二阶幂级数开始系统中便会带有展开状态变量的平方项,就又回到非线性的老路上面去了。我们的目的是让展开后的系统是一个线性系统(Linear System)也就是它必须满足叠加性(Superposition)。例如对于这样一个一般性动态方程:
$$\tag{3-2}
\dot x=f(x,u,t)
$$
其中\(x\)代表状态变量,\(u\)代表系统输入,\(t\)代表时间尺度。一般来说我们是不讨论方程之中显含时间的系统的,因为这类系统一般来说非仿射甚至一般的反馈线性化方案都无法解决这样的问题,我们不在这里讨论。符合叠加原理一定要满足:对于任意两个非全零解\(x_1,x_2\)有任意常数\(k_1,k_2\)使得向量\(x=k_1x_1+k_2x_2\)也是动态方程的解。因此我们仅展开到一阶,但是随着工作点的变化我们会不断的重新进行线性化展开以保证一定的模型精度。
$$\tag{3-3}
\begin{cases}
x_k&=f(x_{k-1},u_{k-1},\omega_{k-1})\\
z_k&=g(x_k,\nu_k)
\end{cases}
$$
上式是一个经过了离散化处理之后的非线性系统,其中\(f,g\)是非线性函数,其他变量仍然具有前文提到的意义。我们必须进行线性化展开的另一个原因是,虽然我们假定\(\omega,\nu\)仍然是一个高斯噪声,但是该噪声经过非线性系统之后叠加在状态变量上就不一定还服从正态分布。对于单变量的系统我们非常好描述它的线性化形式,但是如果面对一个上式中的多维状态变量的系统如何进行线性化展开呢?问题主要出在求导这件事情上,我们遵循以下三条规则展开:
- \(f(x,u,\omega)\)是一个多元函数,其全微分形式为:
$$\tag{3-4}
df=\frac{\partial f}{\partial x}dx+\frac{\partial f}{\partial u}du+\frac{\partial f}{\partial \omega}d\omega
$$ - 为保证线性展开的精度误差控制在一定范围内,我们认为迭代\(x_k\)应当将工作点展开在上次迭代的结果\(x_{k-1}\)处;但是又考虑到我们不可能精确的获得这个点,故而选取上次迭代的估计值\(\hat x_{k-1}\)进行展开:
$$\tag{3-5}
x_k=f(\hat x_{k-1},u_{k-1},\omega_{k-1})
+\left.\frac{\partial f}{\partial x}\right|_{k-1}(x_{k-1}-\hat x_{k-1})
$$ - 而同时考虑到我们也无法精确的获取随机噪声在上一次迭代之中的取值,故而我们将非线性函数计算项之中的\(\omega_{k-1}\)作为0处理,并且新设立一个变量\(\tilde x\)来表示,最后补偿以一个新的经过线性变换的随机噪声:
$$\tag{3-6}
\begin{align}
x_k&=f(\hat x_{k-1},u_{k-1},0)
+\left.\frac{\partial f}{\partial x}\right|_{\hat x_{k-1}}(x_{k-1}-\hat x_{k-1})
+\left.\frac{\partial f}{\partial \omega}\right|_{k-1}(\omega_{k-1}-0)\\
&=\tilde x_k+A_k(x_{k-1}-\hat x_{k-1})+W_k\omega_{k-1}
\end{align}
$$
在上方的线性化展开过程中,我们有一些遗留问题需要解决。首先就是\(A,W\)两个矩阵的计算,我们注意到这个系统是一个多入多出系统,我们假设这个系统是一个\(n\)阶实现,我们可以这样分解原有的系统并且定义相关矩阵:
$$\tag{3-7}
\begin{align}
x_k&=\begin{bmatrix}x_{1k}\\x_{2k}\\ \vdots\\x_{nk}\end{bmatrix}=
\begin{bmatrix}
f_1(x_{k-1},u_{k-1},\omega_{k-1})\\
f_2(x_{k-1},u_{k-1},\omega_{k-1})\\
\vdots\\
f_n(x_{k-1},u_{k-1},\omega_{k-1})
\end{bmatrix}\\
A_k&=\begin{bmatrix}
\frac{\partial f_1}{\partial x_1}&\frac{\partial f_1}{\partial x_2}&\cdots&\frac{\partial f_1}{\partial x_n}\\
\frac{\partial f_2}{\partial x_1}&\frac{\partial f_2}{\partial x_2}&\cdots&\frac{\partial f_2}{\partial x_n}\\
\vdots&\vdots&\ddots&\vdots\\
\frac{\partial f_n}{\partial x_1}&\frac{\partial f_n}{\partial x_2}&\cdots&\frac{\partial n_1}{\partial x_n}\\
\end{bmatrix}_{\hat x_{k-1},u_{k-1},\omega_{k-1}}\\
W_k&=\begin{bmatrix}
\frac{\partial f_1}{\partial \omega_1}&\frac{\partial f_1}{\partial \omega_2}&\cdots&\frac{\partial f_1}{\partial \omega_n}\\
\frac{\partial f_2}{\partial \omega_1}&\frac{\partial f_2}{\partial \omega_2}&\cdots&\frac{\partial f_2}{\partial \omega_n}\\
\vdots&\vdots&\ddots&\vdots\\
\frac{\partial f_n}{\partial \omega_1}&\frac{\partial f_n}{\partial \omega_2}&\cdots&\frac{\partial n_1}{\partial \omega_n}\\
\end{bmatrix}_{\hat x_{k-1},u_{k-1},\omega_{k-1}}
\end{align}
$$
关于以上矩阵运算和线性化方案之中\(\tilde x_k,A_k,W_k\)虽然看起来是一个函数或者变量,但是在单次迭代之中事实上是代入了\(\hat x_{k-1},u_{k-1},\omega_{k-1}\)等变量之后的常数,只不过这些量需要在每次迭代之中反复的重新运算而已。整个系统就此来看依旧符合线性的卡尔曼滤波器的推导,但是具有极大不同的一点是,过程噪声的协方差矩阵变成了动态计算的:
$$\tag{3-8}
Q_k=E\{(W_k\omega_{k-1})(W_k\omega_{k-1})^T\}=W_kE\{\omega_{k-1}\omega_{k-1}^T\}W_k^T
=W_kQW_k^T
$$
基于同样的求导方法、近似算法,针对非线性系统模型之中的测量方程部分也可以进行线性展开,并且同样计算新的测量噪声协方差矩阵和\(\tilde z_k\)如下所示:
$$\tag{3-9}
\begin{align}
\tilde z_k&=g(\tilde x_k,0)\\
z_k&=\tilde z_k+H_k(x_k^m-\tilde x_k)+V_k\nu_k\\
H_k&=\left.\frac{\partial g}{\partial x}\right|_{k-1}\\
V_k&=\left.\frac{\partial g}{\partial \nu}\right|_{k-1}\\
R_k&=V_kRV_k^T
\end{align}
$$
3.2 EKF下五个方程的新把戏
有了以上的运算和非线性系统线性化展开之后,一切就又回到了线性卡尔曼滤波器的正轨上,但是EKF之中有些迭代计算的细节有所改变,但是整体根据五个方程进行迭代的方案仍然是不变的,这些步骤可以表达如下所示,构成一个完成的迭代步骤:
- 首先先验估计直接使用\(\tilde x_k\):
$$\tag{3-10}
\hat x_k^-=\tilde x_k=f(\hat x_{k-1},u_{k-1},0)
$$ - 其次计算先验误差协方差矩阵,并且附带计算新的线性化\(A_k,W_k,Q_k\)矩阵:
$$\tag{3-11}
\begin{align}
M_k^-&=A_kM^{k-1}A_k^T+Q_k\\
A_k&=\left.\frac{\partial f}{\partial x}\right|_{k-1},W_k=\left.\frac{\partial f}{\partial \omega}\right|_{k-1},Q_k=W_kQW_k^T
\end{align}
$$ - 校正阶段的增益正常计算,但是仍旧要附带计算新的线性化的\(H_k,V_k,R_k\)矩阵:
$$\tag{3-12}
\begin{align}
K_k&=\frac{M_k^-H_k^T}{H_kM_k^-H_k^T+R_k}=M_k^-H_k^T(H_kM_k^-H_k^T+R_k)^{-1}\\
H_k&=\left.\frac{\partial g}{\partial x}\right|_{k-1},
V_k=\left.\frac{\partial g}{\partial \nu}\right|_{k-1},
R_k=V_kRV_k^T
\end{align}
$$ - 后验估计的计算之中大部分与线性部分相同,但是计算误差时为了提高精确度,使用\(\tilde z_k\)的非线性形式,与先验估计之中使用非线性估计方法一样:
$$\tag{3-13}
\hat x_k=\hat x_k^-+K_k(z_k-\tilde z_k)=\hat x_k^-+K_k[z_k-g(\hat x_k^-,0)]
$$ - 最终的后验误差协方差矩阵计算没有任何差别:
$$\tag{3-14}
M_k=(I-K_kH)M_k^-
$$
3.3 写在最后
卡尔曼滤波器总结来说是一种高效的,较为适合嵌入式和小型化设备实现的滤波器,主要用于线性动态系统的状态估计,其主要应用的领域除了普通的信号处理之外主要在于运动控制系统、导航系统、计算机视觉等等。近年来主要应用的领域据笔者了解有:
- 导航与辅助定位:在GNSS定位,航空航天导航系统之中广泛的应用。事实上这就是当年鲁道夫·卡尔曼创造卡尔曼滤波器时的主要目的,现在世界各地的导航系统以及外层空间的支持设备事实上已经在全球构成了一个巨大无比的卡尔曼滤波器。
- 基于SLAM的定位:在机器人工程之中,常常用于在建立地图之后结合机器视觉和激光雷达进行位置估计和环境映射——事实上其实也属于导航系统之中的一类。
- 普通信号处理:用于处理包含高斯噪声或者类高斯噪声的信号,例如雷达信号、IMU进行姿态解算过程之中的运动信号、语音信号等等。
- 经济金融:这方面笔者不甚了解,只知道用于时间序列分析,估计未知状态,指导量化交易这些。
并且除了本文提到的扩展卡尔曼滤波器(EKF)之外还有其他的变种和优化方式,用于卡尔曼滤波器在各种应用方向和应用场景之下的限制带来的不便的解决,笔者所知道的变种和优化方式主要有:
- 扩展卡尔曼滤波器(EKF):这种主要用于处理非线性系统,用上文提到的线性化方式处理非线性系统和非线性环节,个人认为是一种较为粗糙但是处理方法非常简单有效的线性化处理方法。
- 无轨迹卡尔曼滤波器(UKF):这是另一种处理非线性系统的方法,建立了一种称作\(\sigma\)点的理论来近似非线性的分布函数,个人认为擅长于处理非线性系统噪声。
- 连续卡尔曼滤波器(CTKF):全称应当是连续时间卡尔曼滤波器,是卡尔曼滤波器一种连续时间系统下的变体,去除了离散化的部分。这种滤波器主要是应用于对实时性要求极高,采样系统可能出现信息丢失的情况,例如飞行器和轨道卫星的运动学解算、超高速通信系统的信号处理等等。
- 适应性卡尔曼滤波器:通过灵活调整过程噪声和测量噪声的协方差矩阵,自动化的调整性能以适应系统,随着近年来NN和LLM领域的突破,这种自动调节变得越来越现实。
- 信息滤波器:使用信息矩阵和信息向量而不是状态估计和协方差矩阵,笔者了解不多。
读者和卡尔曼滤波器的使用者应当意识到,卡尔曼滤波器虽然看起来不是那么简单,但是仍旧是一个完整的控制系统之中的一个部件而不是整体。卡尔曼滤波器终究需要与其他的控制框架相结合才能够得到更好的控制效果,才能够得到“1+1=>2“的效果,个人认为较为适合结合卡尔曼滤波器使用并且当前正在热点使用的控制方法有这些:
- 经典的PID控制器:结合非常常见的PID控制器的离散实现,可以轻易的提高系统的控制精度,这种组合非常常见并且应用极其广泛,或者也可以说PID控制器作为某种“概念神”事实上可以兼容大多数的观测器和滤波器,总之卡尔曼滤波器和PID的结合不可不会,不可只会。
- LQR,所谓的线性二次调节器,事实上可以推广到整个线性动态规划和Bellman的那一套东西上面去,本人曾经尝试过与LQR相结合,在不确定性噪声较大的系统之中有奇效。但是如果要应用于很流行的LQR控制器+类倒立摆系统这样的非最小相位系统之中,需要注意延迟和相位裕度。
- 自适应:卡尔曼滤波器的实现思路结合近年来流行的一些无模型卡尔曼的实现方法能够很好的用于估计自适应控制算法之中系统参数的不确定性,提高这种方法对于不同真实系统和不同控制策略的适应性问题,算是良好的结合。
- MPC/NMPC:与模型预测控制结合是笔者认为在机器人控制与多智能体控制领域最好的应用结合和研究方向之一,卡尔曼滤波器可以提供MPC需要的准确状态估计,针对于MPC这样的实现结构和控制策略理论上可以发挥出非常良好的性能。
笔者常常以此自勉,并且希望读者也有这样的认知:卡尔曼滤波器是一个经典的、精妙的理论,鲁道夫·卡尔曼本人对于自动控制理论和自动控制理论工程化的推动和贡献是可以永载史册的,甚至我个人认为鲁道夫·卡尔曼仅仅在自动控制理论的领域是和钱老先生同等地位的——这个理论体系缺少了他们真的会变得无趣很多,变得破破烂烂。但是我们仍旧要意识到卡尔曼滤波器虽然从理论上来说很精妙,但是仍然在工程实践上具有一定的局限性和使用难度,对于初学者而言常见的挠头问题就是:
- 推导居然是基于状态空间表现形式的,而我只了解经典控制甚至说只会单纯的使用PID代码
- 乱七八糟的参数到底怎么调整,我从xxx处借鉴来的参数为什么不能够很好的工作
- 我没有系统模型,也没有什么建立模拟系统的想法,我就是温度传感器的电压老是抖来抖去而已,卡尔曼滤波器难道就没有应对这种情况的同样牛逼闪闪的方法么
- ……
所以学习卡尔曼滤波器不仅仅要明确推导过程,更要明白我们为什么要这样做,我们为什么会想到要这样做,这样做有什么好处……基于这些考虑本文很多部分显得又些过于基础,过于冗长甚至到了笔者认为略有臃肿的地步——但是笔者坚定认为我们不应当忘记卡尔曼滤波器从设计的初衷开始就是着眼于工程实际而不是做一个密不透风天衣无缝的理论体系或者弄出一些精巧炫技而没有实际作用的Math Tricks的。因此了解了卡尔曼滤波器的思路和推导过程之后,仍旧希望大家了解更多的改进、变种、应用实例。关于参考资料,各种文献库之中的论文笔者就不列举了,但是在扁平化理解卡尔曼滤波器的道路上笔者认为以下两个内容值得细细观看,反复观看:
- 首推就是B站UP主DR_CAN老师的相关合集视频,王老师的书《控制之美》第二册之中有着更加详细更加严谨的书面化推导,希望大家买入,希望大家支持老师。由衷的说一句DR_CAN老师是我在控制理论领域在B站发现的宝藏UP主,推荐读者们详细翻看边边角角。
- 其次就是国外的一片博文图解卡尔曼滤波器,这篇文章在Reddit论坛关于卡尔曼滤波器的讨论之中广受好评,本文封面取材于此,整篇文章从一个非常接地气的例子入手深入浅出,强烈推荐。只不过通篇文章全英文写成并且由于服务器位于国外可能加载时间过长不太友好。
感谢楼主的贴子,令我非常疑惑的一个点是有没有可能输入u是一个随机的量,在摆动案例里的外力F如果是随时间随机变化的,在预测先验估计时是如何让uk-1作用的